
What version of Ansible are we up to? 2.5?? Seems like just yesterday I started using Blocks for error handling. Even more recently, I decided to retrofit some of my roles with the new yum_repository module which allowed me to drop my repo file templates. The point is, Ansible is constantly adding and deprecating functions that may change the way you go about writing your code. One thing that should seldom change is how you organize your code. But is directory structure all we need to worry about?
There isn’t one right way to organize your work, but there are many wrong ways, Ansible is flexible enough to enable some pretty bad coding practices.
Ansible Worst Practices
Look around the interwebs, and you’re sure to find plenty of “Best Practices” for Ansible. I think that the term “Best Practices” gets overloaded, overused, and overly relied upon. Often, certain aspects fall through the cracks and don’t receive any attention on these Best Practices blog posts. Many people read the lists and think “My code doesn’t follow best practices to the letter but it works so I am not too worried.” So instead of writing another Best Practices post I went the other direction. Here are a few no-no’s:
Overuse of comments
Ansible is declarative for a reason. Your code should document itself. Tasks should have descriptive names that explain what is happening in that task. Overuse of comments, however well-meaning, leads to congested code that requires more maintenance if changes need to be made. It also sets a dangerous precedent and other developers may start commenting with important information that will become buried in the code. Keep your README updated and your Tasks names sharp.
Mixing YAML syntax styles
Pick one! Yes, your code works but it’s bad form and super annoying. If you’re going to indent parameters, don’t suddenly start equating them. Here’s an example of this behavior for your entertainment.
- name: Ensure selinux is set to permissive
policy: targeted
state: permissive
- name: Download the Ambari repo
get_url: url={{ hdp_ambari_repo }} dest/etc/yum.repos.d/ambari.repo
- name: "Create hostname entry to self '{{ inventory_hostname }}'"
lineinfile: dest=/etc/hostname state=present create=yes regexp='.*' line='{{ inventory_hostname }}'
Failing to strive for idempotency
If you aren’t focusing on writing Idempotent roles, you should be. Most people run into this pitfall when using certain modules like Command. When using command alone, Ansible will always run the command and mark the task as changed even if nothing has actually changed on the host.
Here is a simple example: I want to enable the optional repo if it’s disabled.
If I do it like this, the task will show as “changed” no matter what.
- name: Enable optional repo
command: yum-config-manager --enable {{item}}
with_items:
- optional
Let’s try this instead:
- name: Gather enabled repos
command: yum repolist enabled
register: enabled_repos
changed_when: False
- name: Enable optional repo
command: yum-config-manager --enable {{item}}
when: '"{{item}}" not in enabled_repos.stdout'
with_items:
- optional
Now, when these tasks run, they will only show 1 change after Ansible evaluates the when and determines if the criterion is met.
Role Sprawl
Is your role doing too much? When writing a role, keep in mind what the role must accomplish. Once you start expanding beyond the express purpose for the role, you have code that could install superfluous software/configurations on yours and other systems. Use role dependencies to combat role sprawl.
For example: You want to write a role to install MySQL. You include all the necessary bits and pieces to get MySQL installed on multiple Linux distributions but you remember that one of your use-cases requires a JDBC driver. The little red devil on your shoulder says “Just add a task to the role! Who’s it going to hurt?” The little angel pops up on the other shoulder and says “That’s not an appropriate place to install that driver! That driver should be a dependency for whatever software requires it!” Besides the fact that you have 2 nerdy-ass supernatural beings hovering around you, the angel is right.
Variable precedence
Back in the days of pre-2.0 there was a lot of “magic” parsing in Ansible, and there were just five levels of precedence to deal with. Also, includes got evaluated as pre-run instructions. Now there are 16 levels of precedence. This is great in terms of functionality but can trap the unwary, especially when pre-2.0 behavior is taken for granted. First off, grok this diagram:

Variables are set and parsed at runtime, and vars in includes won’t magically be loaded and ready when you start a playbook run (unless you’re importing; see below). This is possibly the number one reason playbook migrations fail: pay attention to variable precedence. If you want to load variables before the first task executes try the pre_tasks section.
Also, you might want to avoid idiomatic variable references with loops like this:
With_items: foobar # what’s foobar — a variable or a string?
This was okay with pre-2.0 magic, but can have consequences when you deal in Ansible 2+.
Understanding Role Structure
When organizing roles and playbooks, you have to look beyond directory structure. Yes, the directory structure is an important aspect, but it’s just the tip of the iceberg. Besides, Ansible has already documented this fairly well and if you pull a role from Ansible Galaxy, many contributors adhere to ansible guidelines.
So let’s walk through a typical role to get a deeper understanding.
- defaults: Like the name says, this is where you would place your variables that come with the role and are necessary for the role to run successfully out of the box. These variables will all have values but are easily overridden if you don’t want to accept the default values. In the variable order of precedence, defaults are in the weakest position.
- files: The files directory is where you host files essential to the role. Keep in mind that you should not be passing in large files from your role. Github has placed a strict 100MB limit for files in a repo so this tends to act as a good rule of thumb, even though it is not limit for Ansible. Make arrangements to host large files in an appropriate place like S3 or an artifact repository.
- handlers: Handlers are just tasks that are run when notified by another task. One of the main uses for handlers is to manipulate services. Remember, the service you are trying to manipulate has to be configured properly. You can’t tell Ansible to restart a service if that service doesn’t have a daemon running.
- meta: Typically, the only two variables typically defined in meta are galaxy_info and dependencies. When writing roles with multi-platform support, this is where you will list the platforms your role will support. This is also where you list the dependencies for your role. Do you have any roles that require other roles to run first? This is the spot where you would list them in the dependencies list.
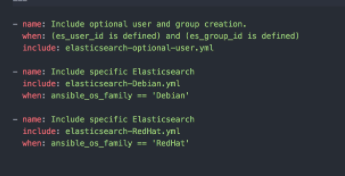
- tasks: The general rule is to write task files (like install.yml, configure.yml) and include these in your tasks/main.yml file. Many times you will have OS/platform specific tasks and variables and you will want to segregate them in separate files. I will talk more about this concept later in the post but for now, take a look at the Elasticsearch galaxy role for example.

Elastic breaks down tasks into OS specific task files, and shared task files. Some files will apply to both OS version while others require conditionals to ensure the correct tasks are run.
I wouldn’t recommend having too many layers of ‘includes’. It makes it difficult to follow the little white rabbit (thereby missing the chance to meet Trinity…but I digress). - templates: Files placed in the Templates directory are processed by Jinja2 templating engine. Convention dictates using the file extension .j2 to indicate that your files are using jinja but its not actually necessary. But you should do it anyway.
- vars: Many times, people get confused about the difference between defaults and vars. The main takeaway is the order of precedence. When organizing your role, you may have variables with values that are absolutely necessary for the role to succeed in its current form. These values are not meant to be overridden. The user of the role will understand this because you put them in vars/main.yml rather than defaults/main.yml.
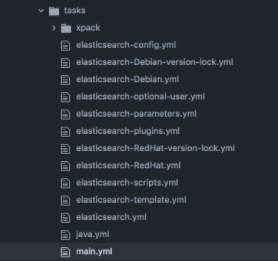
What roles go where?
When you write your own roles, you are responsible to maintain them. If you decide to pull roles from Galaxy or GitHub, you should not be maintaining them but pulling newer versions as needed. A good way to stay organized is to put these two roles in two different directories: roles and galaxy_roles (you can name this whatever). When you organize your roles in this way, it lets anyone who gets a hold of your code know that these roles are being used but not being modified or maintained by you or your project team.
You will need to make a change to your ansible.cfg to facilitate this change:
`roles_path = ’
Includes and Imports
We touched on this briefly above but it deserves further discussion. Ansible 2.4 gave us the ability to call a role/playbook/task from within a playbook differently than in previous versions. If you have code in a different file, large amounts of code broken into multiple files or organized code logically into separate files, there are a ways to use it without having to add the code word for word into your playbook.
There are two options: includes and imports. These two methods differ from Roles in the sense that they are not fully packaged with everything they would need to run independently. But they allow you to break your code into smaller files which can be called elsewhere. You can also call tasks from a role without including the entire role.
tasks:
- name: Ensure AWS assets are terminated
include_role:
name: aws
tasks_from: retire.yml
They also differ from one another because of when they are parsed by Ansible. Import statements are preprocessed when you run the playbook. Include statements are processed the moment they are encountered during runtime.
There are pros and cons for each that should be carefully considered and they will affect how you write and organize your code. First, you can’t use import with loops. Also, if you use import, you will not have access to variables from inventory sources such as host- or group_vars.
If you try to run -list-tasks, it will not show tasks inside an include. You cannot use notify to trigger a handler from inside an include. For more detail on the difference between import and include and how to use them, check out Creating Reusable Playbooks.






0 Comments