
When we think of architecture in general, we think of a static plan for a structure. I mean, it’s as if we’re building a house and we need a plan. However, plans do not always take into account situations when fundamental assumptions have to change and shift to match circumstances. For example, what if that house was designed for level ground and suddenly the ground becomes a sand dune? How would you account for that in an architecture?
Thanks for your patience as I waxed abstract. Now let me tell you the story you came to hear.
We were engaged by a global finance powerhouse to move their installation of a popular business intelligence product from their datacenter to the cloud. The basic premise was simple enough — create the environment in Amazon Web Services (AWS), install the software on the Elastic Compute Cloud (EC2) instances, connect the relevant data sources, and automate the entire process to be repeatable across multiple environments from development to pre-production. Automating infrastructure is something that we at Oteemo specialize in, and we were happy to help them structure a true cloud migration for the application. However, as it turned out, it was easier said than done.
Ch-ch-ch-changes
The client had a very substantial cloud presence involving multiple providers. They had enacted architectural decisions that, while in line with best practices, could affect the flexibility of this migration effort. That was just the proverbial tip of the iceberg. Financial technology requires strict compliance with data protection and privacy laws, and that meant rapidly adapting to an ever-evolving security posture.
We worked closely with a core team of application specialists and cloud engineers with deep domain knowledge and that made things easier to implement. However, their knowledge of their organization — and who to approach to clear which impediments — evolved as we got closer to the finish line.
The Way We Build
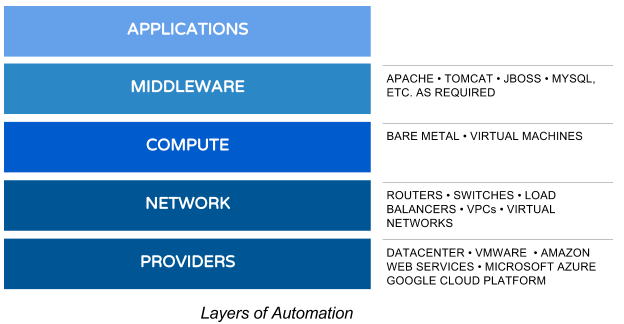
We try our best to automate in layers. Not only does this allow us to build versionable environments completely as code, but it also enables switching out generic components with provider-specific services where appropriate. For example, let’s say we need a MySQL-compliant database in AWS. We could use an EC2 instance or more to host the database, but that would add yet another piece of compute we have to maintain and patch. Why not use AWS’ Aurora DB on their excellent RDS managed service instead? Similar services exist in Azure and Google Cloud Platform (GCP). The provider or hypervisor doesn’t matter since you can cater to every variation of your architecture if you keep the couplings loose enough. In this engagement, this ability to quickly change and scale became critical to our success.
Our goal was to provide a framework for application migration. The same framework can be used, with relatively minor customization, to migrate different applications to the cloud.
The Tools of The Trade
Although we work with client preferences in orchestration and configuration management, our tool of choice is Ansible. It’s agentless, speaks SSH and Powershell, and controls everything from network equipment to complex application stacks. Coupled with the role-based security and the centralized REST API of Ansible Tower, Ansible provides a configuration management (CM) solution that is hard to beat. We have also been known to use Terraform and Chef on occasion, but Ansible remains the favorite because of its ease of use, extensibility and declarative nature. Ansible allows you to describe your target infrastructure state in easy-to-understand YAML, and uses its modules to enforce that state.
In this engagement we used Ansible Tower and ManageIQ as key tools. These were installed in the on-premise VMWare environment looking out to AWS, and provided a single control surface to automate the cloud migration effort.
Setting Up
Research began early. We built out a silent install of the application in AWS, both for Windows and Linux. The client chose the Linux version of the application for cloud deployment. The target architecture came next.
The BI tool was a monolithic COTS application that was not originally engineered for cloud deployment and the vendor’s technical support team wasn’t very helpful. We worked out the modalities based on their recommended best practices for on-premise hardware, and then did a “cloud pass”, deploying AWS-specific services to optimize the install. All of this was coded declaratively in Ansible. The end result was an optimal deployment that could be readily promoted to higher environments with relatively little effort.
We drafted and tested the build in a sandbox environment, which was an AWS sub-account owned by the client. It had security controls similar to their regular development environment, but was not connected to their internal network. Once we had validated the install in the isolated environment, the Ansible code was used to generate an identical situation in the actual development environment. This is where things got interesting.
Access Denied
The development environment in AWS was connected to the on-premise network with AWS Direct Connect, making it a quasi-extension of the client’s network. This meant that the stringent security controls in the client network would apply. Each access restriction would add additional time to the project schedule, leading to frantic parlays across departments to make the unusual happen.
Usually, we tend to use a multi-VPC architecture on AWS. A management VPC hosts all the tools and repositories and development VPCs hold the working instances. We can launch all of this from scratch. However, the client chose to standardize on a single-VPC architecture, and making any network or security level changes was prohibited. Since we built in layers, adapting to this change was simple. We just deployed to the VPC and subnet given us, thereby maintaining complete compliance with security demands.
The next challenge involved service accounts and access credentials. The client had a comprehensive and lengthy process for provisioning and activating security credentials. A requirement to incorporate Hashicorp Vault as a SSL backend prompted yet another partial re-engineering of the solution, but the overall impact was minimized by the modularity of the infrastructure code. Similarly, a mandate to enforce Centrify across all instances was swiftly dealt with by minimally tweaking the deployment process and relaunching from new compliant AMIs.
The Moral of the Story
In the end, everything but the licensing process was automated, including ODBC connections for connectivity to on-premise databases. The in-house cloud migration team was mentored throughout the development process. They took over the reins, successfully completing the deployment and testing of the new “cloudified” application. Eventually the process would be repeated for higher environments.
This engagement was full of lessons for both the client team and for us. Here are some of the lessons that we learned, which can help you get past unexpected roadblocks and challenges as you plan your next cloud migration.
- Assess what you have to work with: Take a detailed inventory of the current state of the application being migrated. Identify the stakeholders and decision makers, and involve them early in the planning. Communicate the impact of the migration to them as clearly and frequently as you can. Their support will be vital when you need those pesky blockers removed.
- Survey the security landscape: What service accounts and credentials will you need? SSL certificates? Security and compliance baselines? Which security controls can you operate, and which ones can’t you touch? Who is your security resource person? Involve them early as well. Give them a say in the process, beginning at the architecture, and make sure they are as invested in the solution as you are.
- Substitute ingredients for better health: Use cloud native services where appropriate, and minimize the operations and management (O&M) impact of your solution while maximizing cost-efficiency. The CloudOps gang will thank you, and so will the accounting department (We can dream, can’t we?)
- Design for Repeatability and Scalability: Try to parametrize specific infrastructure detail into manifest files. The best outcome would be a set of playbooks and roles that can be fed a manifest detailing the environment needed. These manifests can then be versioned to make variations for specific versions and environments, giving you ultimate flexibility.
- Mentor from Day One: No system works in a vacuum. You’re not making something that only you will use. Teach as you build. This gets the client team more invested in the project, and beats the frenetic last-minute handover/training sessions and gap-ridden documentation.
- Test, learn, improve, repeat: Test driven development will save you hours of anguish. Use a test framework like Test Kitchen (Chef) or Molecule (Ansible) and test your infrastructure like you’d test application code. Test until you’re blue in the face, then test some more.
- And finally, build to change: “How easy would this be to change after I am gone?” Ask yourself this every moment you architect and build. Your approach to building for change will dictate final success in a dynamic environment.






0 Comments