
There are many principles and approaches to building good, modern software, but at the heart of all of them is the Principle of Modularization. Modularization is the breaking down of something into logical, bit-size chunks, that fulfill a very specific purpose. Many such bit-size chunks, or modules, can be put together and used in collaboration, to create a complete system that can do wonders. Let’s look at what modularization is and how to implement it, including techniques such as Strangler Pattern, Functional Breakdown, and isolating Data, Interfaces, and Processes (DIP).
Why Modularize?
So, what does Modularization get you, and how can it improve your Software Product? Let’s look at some examples.
Components and Features Analogy
The automotive manufacturing industry has been using modularization for years, creating separate components for vehicles that are highly specialized, that when put together, make up the cars we drive. Consider the components in your dashboard. Some cars support digital radio, some Bluetooth connection capabilities, others video playback features, or the ability to plug in external devices to charge them or play music from them, and the list could go on. Each of these sets of features is very distinct and unique, yet they all reside as different configurations of the same dashboard space. Many Software Product Components and Features act very similarly, working within a shared environment or dashboard, with the ability to have them interchanged or toggled on and off, and each dedicated to a particular function. A good example are Web Components or Widgets, which are bundled functionality designed to operate within a given user interface or dashboard space.
Imagine that each of these features or components could not be separated and developed independently from the dashboard, but had to be included as part of the same initial dashboard build. If we had 7 such components, we would have to build 7 distinctly different dashboards, even though the other portions of the dashboard (in the case of automotive, vents, lights, etc., in the case of Web Component Dashboards, user log-in and menus, dashboard preferences and controls, site styling and basic user interface and experience, etc.) may be exactly the same. None of the features are separate components or modules, so none can be reused, and things that might be the same between the dashboards, such as vents, headings, and menus, would have to be re-created and re-defined on every dashboard. Going back to our Web Components example, this might be analogous to copying a dashboard and adjusting its features. Totally separate dashboard and totally separate configuration and adjustments, even though it was copied from an existing dashboard, that shares many of the same features and capabilities.
Pipelines and Assembly Analogy
Let us consider for a moment how an automotive assembly line might assemble the 7 dashboards we have mentioned. Since each of the 7 dashboards are a single, large module, that cannot be subdivided or built independently, they must each be assembled as one giant assembly stage. All materials for every portion of the dashboard must be available up front before the assembly line can run, and a lot of resources (automation, machinery, people) must be available up front to run the assembly line. That is a lot of moving parts, and a lot of potential defect and quality assurance checkpoints that must be monitored, just for one dashboard. What about the other 6 dashboards – do I pay to duplicate the entire assembly line a second time (automation, machinery, people), in order to assemble more than one dashboard at the same time, or do I assemble batches of one dashboard at a time, and then go through the added resources and effort to switch over the assembly line every time I want to create one of the other dashboards?
Assembly lines can be very analogous to Software Development Build and Deployment Pipelines, where dependencies and code base are pulled together, packaged, built, scanned, tested, certified, approved, and deployed as a final product. Large, undivided codebases and software products, similar to our single-module automotive dashboards, can sometimes lead to long-running, resource-intensive pipelines, that when duplicated across many product lines, can add up in resources and cost.
Defects and Bug Fix Analogy
Returning to our automotive example, what if we needed to update the vents on our dashboards based on a safety hazard that was identified, and perform a recall or update on all dashboards made with those vents? We would need to update the same vents seven times, one for each dashboard we have. To correct the problem for any new dashboards being made, we would need to update the associated assembly lines, for all dashboards. How would we replace the vents in cars that were recalled? We would have to replace the entire dashboard on every vehicle. The replacing of an entire dashboard is labor intensive and will be expensive for our company to perform the recall.
This is similar to finding and dealing with defects and bugs found in your software products and their associated pipelines. Even though the bugs may be for isolated portions of the product, since the codebase is handled as one giant codebase, the entire thing must be rebuilt. All of the pipelines for your product lines must be updated, and providing updates to customers requires a large binary update. Since your codebases for each similar product line are entirely separate copies, it may also involve updating the same things many times throughout your codebases.
A Better Way – Modular Design with Benefits
As many of us know, the automotive industry doesn’t build assembly lines in the way I have described above. Instead, they identify capabilities they will need across multiple product lines, divide them up into smaller components, and build assembly lines to assemble and manufacture those components first. Then, they create separate assembly lines to bring things all together. By building out features, such as vents, lights, etc., as their own, independent pieces, they gain a lot of benefits and flexibility. They can build individual components with smaller assembly lines and fewer resources – they don’t have to wait until all resources for all components are available, just the ones they need. They can pre-build components that can then be used in the assembly of multiple products. If a defect is found, only that component needs correction, and for recalls, only that portion of a product needs to be replaced. If they are smart about how they design their components, they can set general requirements for their components, such as size and power interface needs, that allow them to plug and play many of their components into many different products, in a way that doesn’t require updating and retrofitting. Defects can remain isolated to smaller component sets that are easier to update, mitigate, correct, and replace. If they schedule and plan well, they can build products faster, and with fewer resources.
The same principles apply to software development and production. A large single codebase, like the single build dashboard, is more difficult to maintain. It may have duplicative, non-reusable code that needs to be updated consistently in multiple spots. Making changes to one section requires adjusting or reviewing the entire codebase, and could affect other features that are not isolated. The larger the codebase, the higher the probability of errors and issues with updates over time. Testing of features also becomes more complicated, since we cannot isolate and test features individually.
Breaking up the functionality of our software applications into smaller, logical chunks or modules, allows us to improve or avoid many of the issues we have mentioned. We can update and test features in isolation, without affecting other features. We can reuse functionality, by maintaining it and calling it from one place, and referencing it in many places. All of these things ease the maintenance burden, which over time, leads to less time spent in testing, fixing, and rework, which is a major cost saving. It also allows us to reuse those pieces when we build new features and functionality, decreasing the cost to build and bring to market faster.
How to Modularize – Help my Monolith
So, how exactly should you go about breaking up and modularizing an application, particularly a Legacy, Heritage, Monolithic, or Single-Binary Application? That is something we can definitely consult on, and which may vary from application to application, but here are a few general principles and patterns frequently seen today in the industry.
Strangler Pattern – One strategy to start with, that can provide flexibility for large legacy or antiquated systems, is to first establish a Proxy or Advanced Programming Interface (API) layer, which we’ll call a Facade, between your application, and the requests or entry points coming into your application. Once your Facade is in place, you now have the flexibility to reorganize things within your application and system, behind the Facade, and so long as your Facade is updated to handle routing and translating the requests coming into your Facade, so they get to where they need to go, and results get back to where they need to go, the users of the Facade can continue and do business as usual.
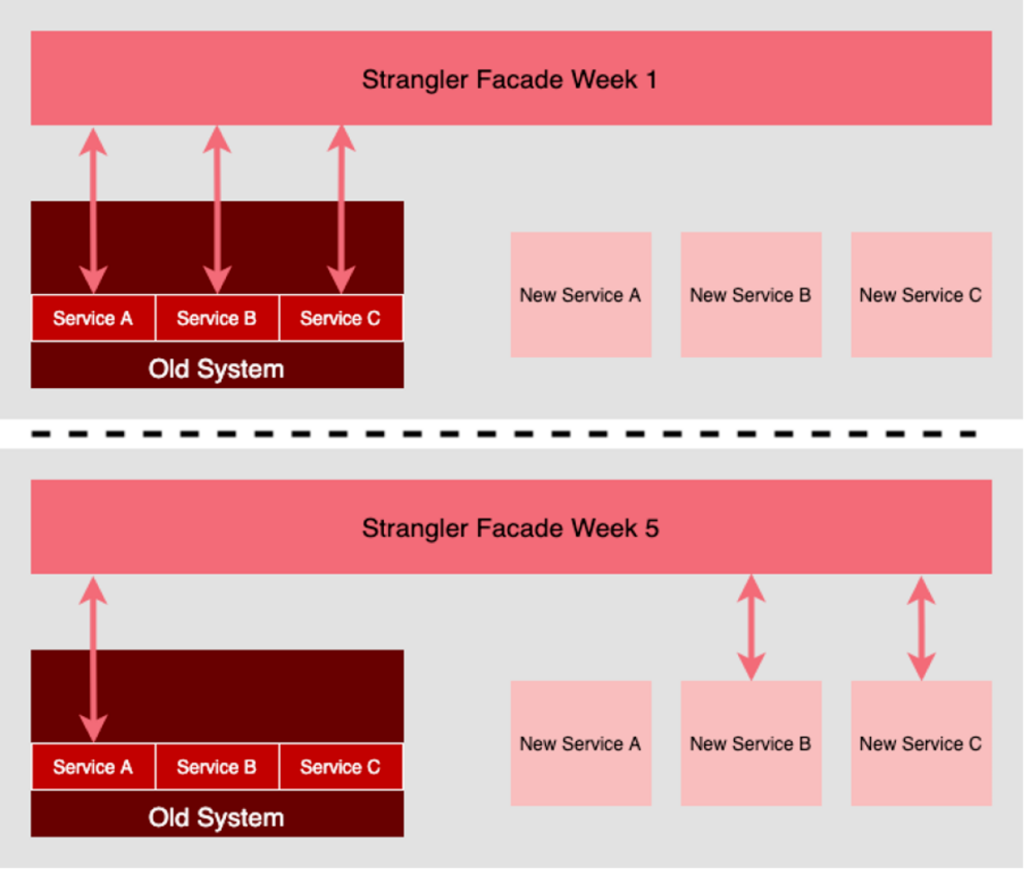
“The pros and cons of the Strangler architecture pattern” – Red Hat
DIP – Data, Interface, Processing. One common approach which has several advantages, is to start by isolating your Data mechanisms, from your Interface and Display mechanisms, from your Business Logic and Processing mechanisms. One of the advantages this provides is the ability to create multiple different interfaces or displays, that still utilize the exact same data and business logic processing. We see this frequently with Web Application Displays and Print features, where the display may change depending on if you are viewing from a desktop computer, mobile phone, tablet, or printing from a printer, though the application and its data have not changed and should be exactly the same. It also allows for separation of concerns, so that changes to one portion of the code can occur, without affecting other sections. It both simplifies development, and helps stabilize the codebase for rapid change and development over time. Even though it will add a layer of additional abstraction, that abstraction will provide you great benefits in the long run.
Functional Breakdown. One simple method for starters, is to go sequentially through your codebase, and comment and divide sections into logical bundles based on the high level function that code is performing. For instance, if you have a bunch of code that is intended to upload a file, and then search for key words and tag the file with them, you might be able to mark the upload file portion as one section, the search or index file for keywords as another section, and the tagging code as another section. Then create a separate subfunction for each of those sections, move the sections into their respective subfunctions, and replace them in the original code with calls to the subfunctions instead. This will require some reworking in order to make the subfunctions work, and you may have to consider such things as whether or not the code can be called multiple times concurrently, instantiation, and other cases. The results of this method, however, are small, bit-size segments of code, that fulfill a very logical purpose. As you move forward, any time you see a similar function section for the same purpose as an existing function, you can ask yourself the question “with a little enhancement in my original function, can it be made to work for both that and this new similar functional case? Over time, you will find your once large and nostalgic legacy code, has turned into a sleek reusable function library.
We see similar techniques employed in Microservice Design, Service Oriented Architectures, the OSGI Model, and Domain Driven Design, just to name a few. While implementing these types of architectural design models requires more than just modularizing your code, many times, modularizing is both the right precursor towards moving towards any of these architectural models, and a requirement.
Modular Mindset
“Modular Mindset” is a design mindset, an approach to modernizing your application architecture, that allows you to create clean, functional, robust, and scalable codebases. With a Modular Architecture, your organization can be more flexible and Agile, and can develop more stable applications faster.
Ultimately, we want small, isolated, functional code snippets and packages, that are maintained and updated in one place, can be used throughout your various applications and product lines, and are easy for your developers to search for, incorporate, and use. They limit blast radius for vulnerabilities and defects, are far easier to maintain and update long-term, and once you have a lot of them, will empower your delivery and development teams to run at the speed of lighting. Establishing a Reference Library of Reusable Code and Templates, and a culture for how to constantly add to, develop, and use your Reference Library, is a great best practice in Software Engineering, and will help you mature and get your Software Engineering Organization and your Software Products, to the next level.
Your developers will need to learn, not only how to modularize an existing application, but how to develop new applications with these same techniques. Oteemo can help you establish a Software Engineering Practice that fosters these and many other techniques within a culture of mentoring and upskilling, that will keep your teams developing great applications for many years to come. Reach out to us here on the website by filling out a contact form, and let us show you what we can do for you.






0 Comments