
Machine Learning (ML) has helped organizations across a wide range of industries make critical decisions with insights gained from their data and its discoverable patterns. Most enterprises have far too much data to examine for them to do it with human eyes. ML leverages mathematical algorithms for analyzing and interpreting patterns in data, which over time enables learning, reasoning, and (hopefully) better decision making.
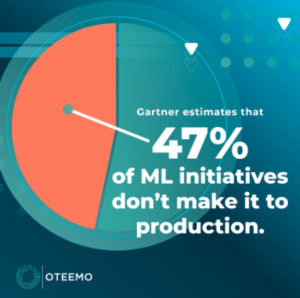
While the benefits of adopting a Machine Learning framework far outweigh the complexity of implementing it, the challenges are formidable and can quickly cascade into a complete project failure. Gartner estimates that only 53% of ML initiatives make it to production. However, there are steps organizations can take during their ML (Machine Learning) project planning that can help ensure their projects ultimately return meaningful results. From the onset of any Machine Learning project, organizations should:
Ensure Data is Easy to Analyze

Successful machine learning projects are primarily dependent on two core components, data and computing resources. The latter is widely available thanks to the proliferation of cloud platforms that grant organizations access to hardware that can operate highly analytical ML models. However, most organizations lack the right amount of data – or precisely quality data – necessary for ML predictions to be accurate. Data is the crucial component that allows ML algorithms to learn while developing context from patterns in datasets. Data needs to be consolidated, optimally structured, and properly tagged for easier analysis.
Build a Data Engineering Framework For Machine Learning Initiatives
Before initiating a Machine Learning project, most organizations misunderstand the need for efficient data pipelines that enable ML models to capture live data and analyze patterns for real-time informed decision-making. As a result, incomplete or imperfect datasets in ML can be the factor that causes a project to fail. Modern applications and systems generate continuous data streams that need to be ingested, cleaned, aggregated, and normalized in real-time before being applied to ML models. Such models need to be able to consume data from heterogeneous data sources filled with an abundance of pre-processed, historical data. For the ease of storage, management, and processing of these data sources, a diligently deployed framework of data pipelines must support the real-time processing of big data, which can include historical context without introducing latency or reducing accuracy.

ML algorithms also typically rely on statistical and probabilistic modelling to map sample input data to output (prediction or decision). Because of its complexity, most organizations fail to create ML models that quantify and assess uncertainties. The resultant is a sub-standard ML system built upon poor data, which leads to an inaccurate model and misses the scope of the business value it was intended to bring. Unchecked uncertainty, therefore, reduces the integrity and ethicality of an ML system’s predictive modelling capabilities.
Understand the Data Requirements
While the applications of ML can be consequential and game-changing, getting there is not easy. Organizations need to understand their data requirements upfront, not just in the tech but also in the processes that support the data. Companies seeking to leverage business-driven automation without spending significant time creating Machine Learning requirements can easily fail to gather not only the right data but also the right insights, significantly reducing their return on investment.
ML Projects can fail for these and a host of other reasons. This is the first in a series of articles that will discuss the fundamental challenges ML projects face and how organizations can greatly improve their odds of success. This first focused on how problems with data quality can doom projects to failure. The next will focus on ML process improvements and where organizations must ensure their gap analysis is accurate to ensure ML success.
Explore part 2 of Why Machine Learning Projects Fail
FAQ’s
Why do we need machine learning?
Machine Learning (ML) helps organizations across a wide range of industries make critical decisions with insights gained from their data and its discoverable patterns. Most enterprises have far too much data to examine for them to do it with human eyes. ML leverages mathematical algorithms for analyzing and interpreting patterns in data, which over time enables learning, reasoning, and (hopefully) better decision making.
What problems Cannot be solved by machine learning?
Machine Learning under the hood is mathematics, specifically, probability, linear algebra, and statistics. Therefore, the type of problems that ML can’t solve include problems that have inadequate datasets, poorly scoped problems, and high uncertainty.
ML utilizes algorithms to find patterns within datasets. Therefore, when there isn’t enough abundance or quality data — no matter what question is attempted in being solved — ML will not be able to solve the problem.
Furthermore, a poorly defined or vague question will lead to an unsolvable solution. However, this is universal to any tool or process, not just ML.
Finally, there are some problems where ML algorithms will have a high uncertainty regarding being accurate. These types of problems can be a consequence from low-quality data or ambiguous questions. But also, these types of problems can arise from cutting edge research where researchers are trying to draw conclusions between two unrelated factors such as the correlation between grey matter and psychiatric disorders. These types of research-based questions are speculative and ML may not be able to produce an accurate model.
Why do most machine learning projects fail?
From Gartner: https://www.gartner.com/en/newsroom/press-releases/2020-10-19-gartner-identifies-the-top-strategic-technology-trends-for-2021
Gartner research shows only 53% of projects make it from artificial intelligence (AI) prototypes to production. CIOs and IT leaders find it hard to scale AI projects because they lack the tools to create and manage a production-grade AI pipeline. The road to AI production means turning to AI engineering, a discipline focused on the governance and life cycle management of a wide range of operationalized AI and decision models, such as machine learning or knowledge graphs.
AI engineering stands on three core pillars — DataOps, ModelOps and DevOps. A robust AI engineering strategy will facilitate the performance, scalability, interpretability and reliability of AI models while delivering the full value of AI investments.
How can enterprises avoid failing at machine learning?
Organizations can avoid failure with ML by investing time in the following areas: business strategy, preparation, and adopting an ML lifecycle management such as ML Ops.
ML is a great tool. However, a single tool can’t solve every problem. Therefore, one’s business strategy should account for which problems ML can’t solve and ensure that the outcome of their ML initiative provides business value.
References
Gartner Says Nearly Half of CIOs Are Planning to Deploy Artificial Intelligence –
https://www.gartner.com/en/newsroom/press-releases/2018-02-13-gartner-says-nearly-half-of-cios-are-planning-to-deploy-artificial-intelligence
Why machine learning strategies fail –
https://venturebeat.com/2021/02/25/why-machine-learning-strategies-fail/
Gartner Identifies the Top Strategic Technology Trends for 2021 –
https://www.gartner.com/en/newsroom/press-releases/2020-10-19-gartner-identifies-the-top-strategic-technology-trends-for-2021






0 Comments