
This blog post is the 1st in a 4 part series with the goal of thoroughly explaining how Kubernetes Ingress Works:
- Kubernetes Networking and Services 101 (this article)
- Ingress 101: What is Kubernetes Ingress? Why does it exist?
- Ingress 102: Kubernetes Ingress Implementation Options (coming soon)
- Ingress 103: Productionalizing Kubernetes Ingress (coming soon)
Kubernetes Networking, Services, and Ingress
If you read till the end of this series you’ll gain a deep understanding of the following diagram, Kubernetes Networking, the 7 service types, Kubernetes Ingress, and a few other fundamental concepts.
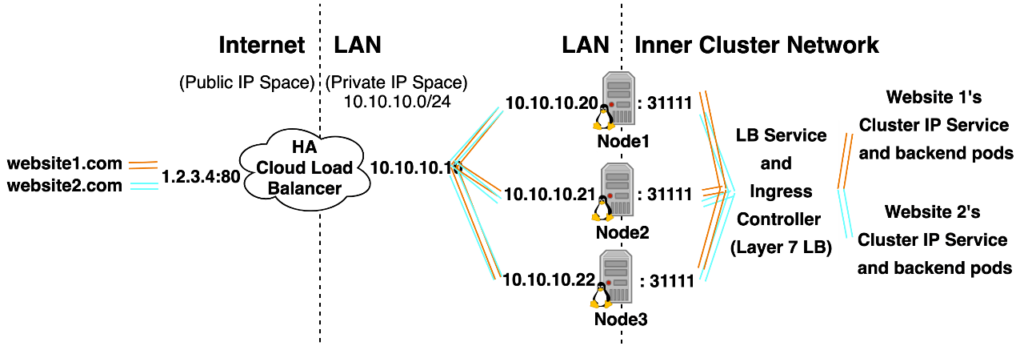
Understanding Basic Concepts
I’ve seen a project with 2 websites and 2 API Groups: Externally accessible APIs and Internally accessible APIs. The External APIs were to function as publicly reachable backend points of entry for the websites and act as potentially reusable building blocks for future projects. Internal APIs were named such to make it obvious that it’d be dangerous to externally expose them as they were meant to house application middleware logic and backend database logic.
The architecture evolved to a point where both the Internal and External APIs were externally exposed using Kubernetes Ingress, firewall rules were implemented to limit access to both sets of APIs. The External APIs were put behind an API Gateway as a means of bolting on authentication functionality, and the Internal APIs were firewalled to prevent them from being externally exposed.
It’s a valid solution, but I’d like to point out that the Internal APIs should have only been internally reachable using a ClusterIP service as this would have been both more secure and less complex. Exposing the Internal APIs over Ingress came about out of ignorance of the basics of Kubernetes / that was the only known way to interact with things in the cluster.
The point of the story is that trying to implement Kubernetes by relying on how to guides can cause you to learn the tool equivalent of a hammer and then see every problem as a nail. If you take the time to deeply learn the fundamentals that advanced concepts are built upon you’ll be able to come up with multiple solutions to problems that don’t have a perfect how to guide readily available and evaluate which solution is best for a given situation. Understanding the how and why of basic concepts improves your ability to do quick solid evaluations of different tooling solutions, which is critical since no one has time to learn every tool in depth.
Generic Networking in a Kubernetes Context
I find abstract concepts are easier to understand and follow when you can build on basic facts, tie in prior knowledge, and parallel abstract concepts with concrete examples. In this section I’ll use those techniques to help explain the following concepts:
- Router’s that do PAT(Port Address Translation) form a network boundary where it’s easy to talk in 1 direction, but hard to talk in the other direction.
- Your Home Router does the job of several conceptual devices combined into a single unit, a Kubernetes Node also does the job of several conceptual devices combined into a single unit, Kubernetes Nodes act like routers, meaning they can do PAT to form a network boundary.
- A single Kubernetes Cluster often belongs to a topology involving 3 levels of Network Boundaries. (Kubernetes Inner Cluster Network, LAN Network, and Internet.)
- It’s common for a single Kubernetes Cluster to have access to 3 levels of DNS (Inner Cluster DNS, LAN DNS, Public Internet DNS)
Router’s that do PAT (Port Address Translation — a type of Network Address Translation (NAT)) form a network boundary where it’s easy to talk in 1 direction, and hard to talk in the other direction.
Routers connect networks:

Switches create networks/allow multiple computers on the same network to talk to each other.
Below is a picture of the back of a home router, which is acting as a Router by connecting Internet Network to LAN, and acting as a Switch by connecting the 4 computers on the LAN to form a network where they can freely talk to each other.
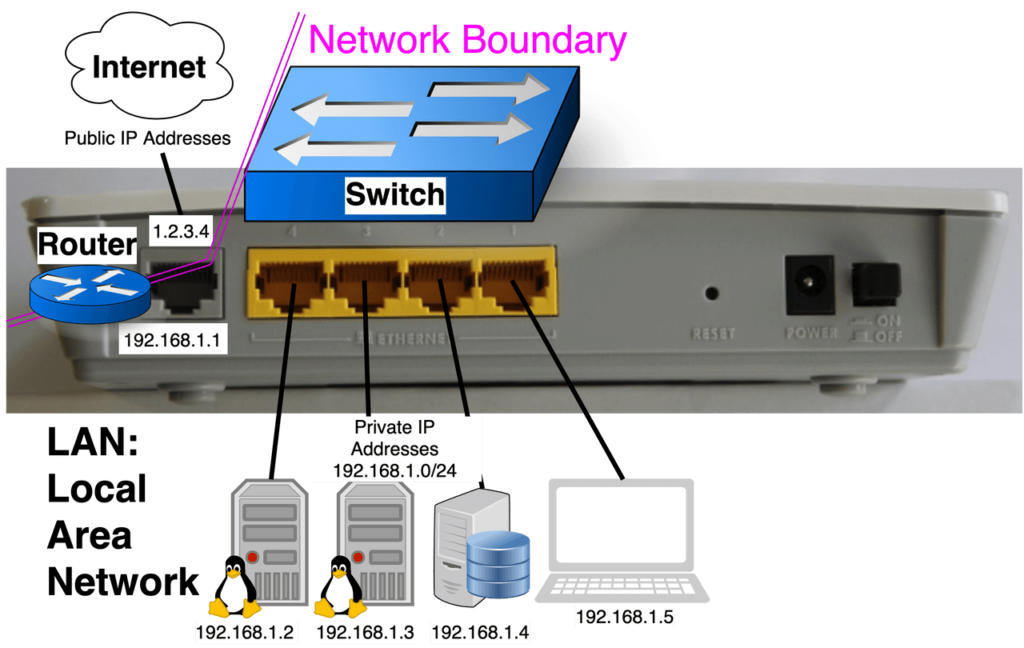
PAT allows 2 things to happen:
- The 4 computers with Private IP addresses get to share a single Public IP Address.
- Computers on the Internet (in front of the Router) can’t start a conversation with computers on the Local Area Network (behind the Router), but they are allowed to reply back. Computers on the LAN can start conversations with computers on the Internet. (This behavior creates a network boundary.)
Your Home Router is doing the job of several conceptual devices combined into a single unit. The pictures of the back of a home router clarify that it’s is a Router and Switch, they often are also DNS/DHCP servers, Wireless Access Points, and sometimes even modems rolled into a single unit. In a similar fashion Kubernetes Node’s aren’t just computers, they act like virtual routers and use PAT to form a network boundary, they also act like virtual switches and create another network:
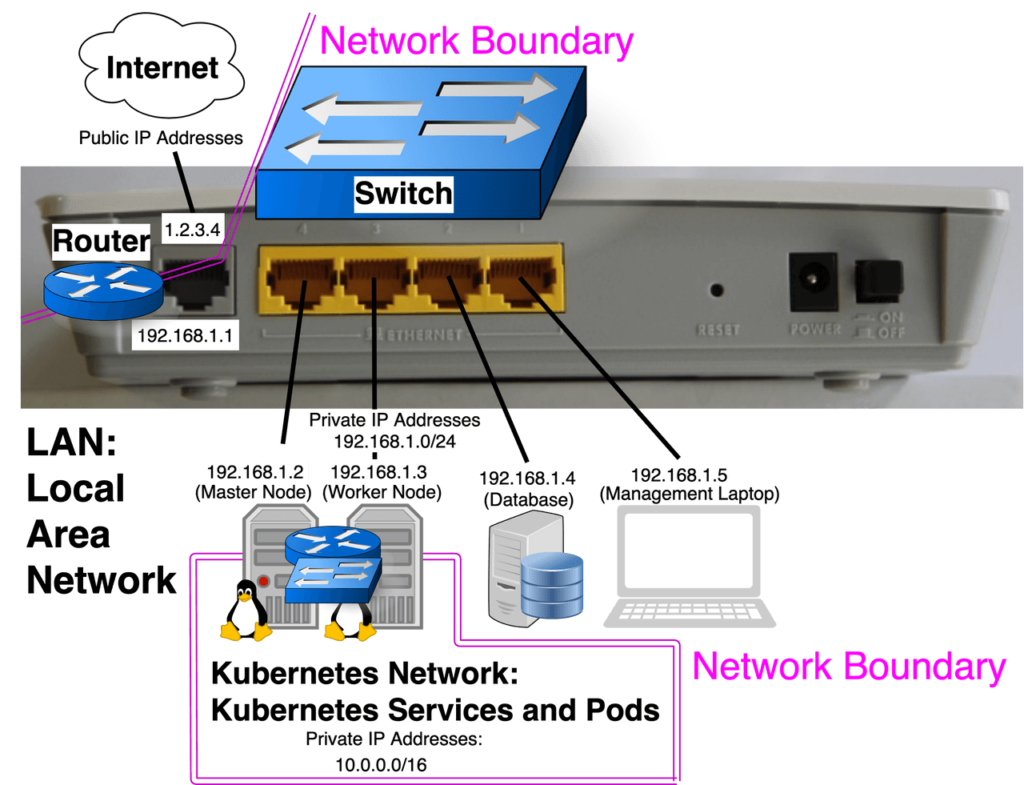
A single Kubernetes Cluster often belongs to a topology involving 3 levels of Network Boundaries.

Default network configuration settings make it so computers on the left side can’t start conversations with computers on the right side, but they can reply to conversations started by computers on the right side. Computers on the right side are free to start a conversation with any computers on the left side.
So by default:
- A computer on the internet can’t start a conversation with a database server on the LAN or a frontend pod in the cluster.
- A Kubernetes Pod can talk to a database server on the LAN, or on the internet.
- A management laptop on the LAN could talk to a database server on the internet, but can’t start a conversation with a frontend pod in the cluster.
This offers a secure default traffic flow to start with, and allowing traffic to flow against the secure default flow requires configuration.
It’s common for a single Kubernetes Cluster to have access to 3 levels of DNS (Public Internet DNS, LAN DNS, Inner cluster DNS)
A pod will have access to all 3 levels of DNS, it can connect to:
- A nginx kubernetes service running in the default namespace of the cluster:
PodBash# curl nginx.default.svc.cluster.local- Note if you use the following commands:
LaptopBash# kubectl run -it ubuntu --image=ubuntu -n=default -- /bin/bash
PodBash# cat /etc/resolv.conf
nameserver 100.64.0.10
search default.svc.cluster.local svc.cluster.local cluster.local
options ndots:5
You’ll realize that pods in the default namespace can shorten the above to
PodBash# curl nginx
A pod in the ingress namespace could shorten the above to
PodBash# curl nginx.default
A SQL database running on the LAN:
LaptopBash# ping mysql.company.lan
S3 storage on the Internet:
https://s3.us-east-1.amazonaws.com/bucket_name/test.png
A Management Laptop won’t be able to resolve any inner cluster dns names, it’ll only have access to websites defined in LAN DNS and Public Internet DNS.
- Note if you use the following commands:






0 Comments