
DevSecOps has become the de facto standard when referring to IT organizations who are looking for increases in collaboration, transparency, and ownership horizontally across the value stream to deliver high-quality products and an increased frequency in delivery.
What to Know About DevSecOps and Your Organization
What Is DevSecOps?
The DevSecOps Operating Model is an instructional roadmap; driving efficiencies, and bringing value closer to your customers.
TL:DR Skip Rant. I’m personally frustrated reading whitepapers describing DevOps or DevSecOps programs, only to see the authors dive straight into a prescribed set of tooling or technology processes that, if adopted, will bring “the DevOps” to your org. It seems they’re trying to package solutions for 85% of “tech” standardization problems whilst ignoring the elephant in the room. Culture. DevSecOps is not fundamentally a technical problem. There are definitely technical aspects that DevSecOps addresses, but the heart of the problem should be prioritized as people and culture, process analysis, and finally, specific technologies that support the former two. No one wants a ¼” drill bit. They want a ¼” hole. DevSecOps targets an outcome that provides ¼” holes, not shiny objects or slick tooling. Rant over.
Why DevSecOps?
In short, because it works! It works because the DevSecOps Operating Model not only creates a venue for security/development/operations in each phase of the software development lifecycle(SDLC), it should also span the entirety of an IT organization. The horizontal flow of value across the value stream is the “What” that successful DevSecOps models target.
DevSecOps is a game-changer for a technical group or organization because it strikes at the heart of the problems that plague so many businesses.
Some core pillars for successful DevSecOps adoption:
- Clearly established executive sponsorship
- Well-formed communication strategies
- A culture of shared responsibilities/goals
- Process analysis and sanity checks
- Automate all-the-things
- Measurements models
- Reciprocity across supportive teams
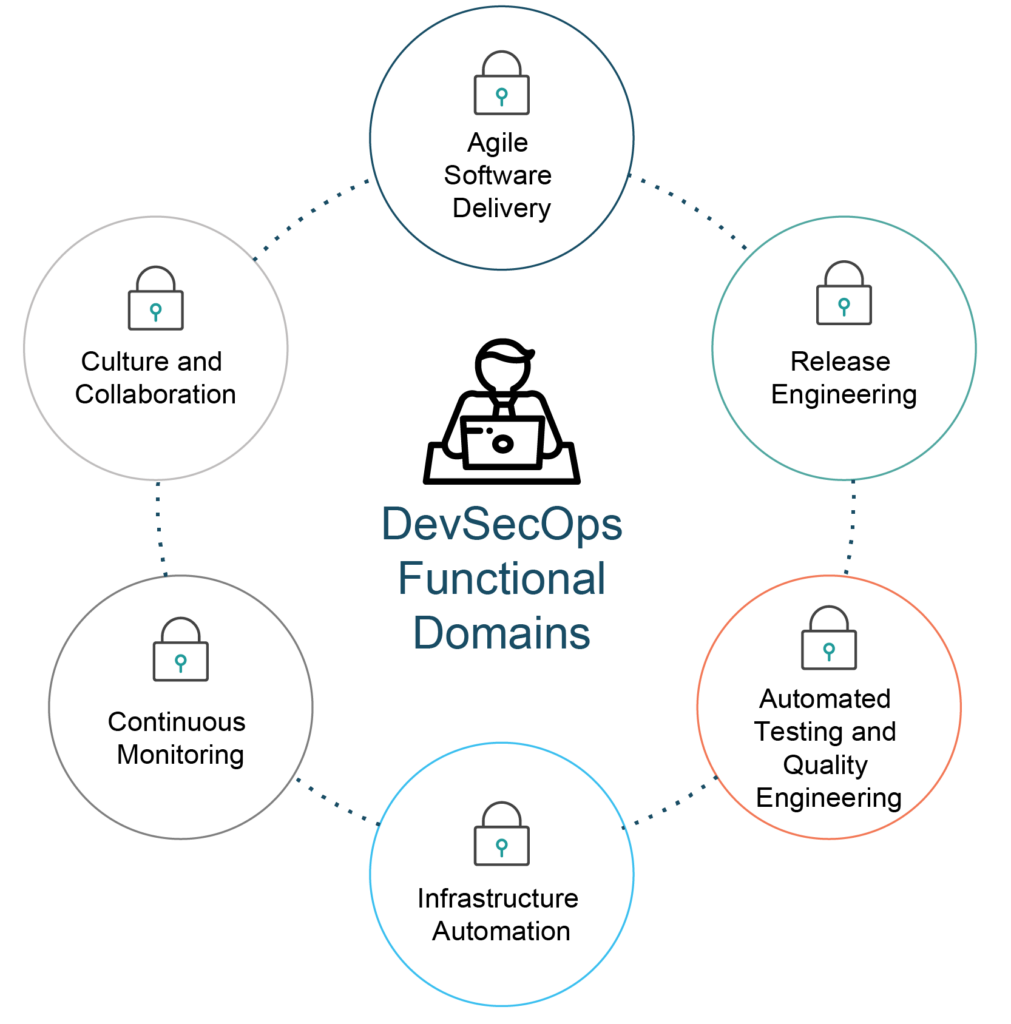
So, in adopting a DevSecOps strategy, where should you start?
Start with your people (because people matter most)
The psychology of your people is at the heart of all success and failure for any company. All of us, regardless of our meta labeling, are simply just groups of people; governments, companies, cultures, nations, races, religions…all groups of people. People are the creators and “how” the people think about DevSecOps is the lynchpin behind success.
Conway’s Law described this very well in 1968
“Any organization that designs a system will produce a design whose structure is a copy of the organization’s communication structure.”
- Melvin E. Conway
Culture & Communication
Clear, honest, and direct communication are essential for establishing healthy, repeatable, predictable processes across an organization. If the communication style shares these characteristics, then the outcomes share those qualities as well. It is highly likely that your people will tell you where the problems lie and may give you hints about where/what you can change to make things better. Again, communication. Ask the questions and you’ll likely get some great answers. It’s the job of leadership to listen, assess and then engage. This is an object lesson to the rest of the group that demonstrates accountability and compassion.
Highly siloed organizations are a norm in today’s large enterprise technology organizations. It has previously been believed necessary that isolated teams understand their responsibilities and needn’t go outside of their respective groups. Conway points this out clearly in his law. Vertical silos incentivize teams to “stay in their lane” and not get involved in discursive activities that pull them away from getting the complex work of writing software done.
We know this to be wrong. Teams succeed by sharing delivery responsibilities. Communication enables negotiation, and ultimately, compromise. Compromise can be painful when you’re not used to it. This takes time to develop. When an executive sponsors communication and collaboration, the adoption is much faster with less organizational friction.
Example scenario:
A microservice is failing and the support staff receives a notification. Ideally, some root cause analysis can be done through a formalized process (5-whys) with the development team who owns the service. This communication provides a better understanding of the cause, improving the ability to re-architect the service. Yet this extra step involves the painful process of communicating across silos, and frankly, it’s easier to simply restart the service and move on.
The method is remarkably simple: when a problem occurs, you drill down to its root cause by asking “Why?” five times. Then, when a counter-measure becomes apparent, you follow it through to prevent the issue from recurring.
Processes and Process Automation
Once clarity, relative to good communication, is established, a field opens to the organization for negotiating and understanding the “why” surrounding the processes that can be ultimately automated. Automating an illogical process – the definition of insanity – is unsustainable and adds to the toil in the life of the most important part of the organization, the people.
Ceremonies with owners across the value stream can identify existing processes with a focus on “why” a process exists. Simply asking ourselves why we have a process can be enlightening, qualifying the process for keep-or-sweep cleanups that lessen the burden on the people who must abide by them. These norms lead to a clearer understanding of success criteria and aid in crafting the goals, short-term and long.
An impartial external analysis can uncover the “sacred cows” in processes. Stakeholders should theoretically be open to dispassionate analysis, a telling sign of organizational maturity vs human behavior.
Everything is software
We are living in the Golden Age of Software. In addition to product or application code, infrastructure components like routing and network fabrics, identity and access models, compliance policies, security scanning, CI/CD pipelines, and all parts of an automated delivery pipeline are built and delivered as software. IP addresses are no longer electrical addresses octets in binary pointing to a specific physical machine. Commonly virtualized (through software) and are functionally the same, the life of an IP address is now a software component and managed-in-software. At the user level, we can now abstract technology to a very high degree, and that’s beneficial for scale and resiliency. It should also provoke rethinking how security and compliance are structured in an IT organization.
If everything is software, then delivering software changes and features should fall within a software development lifecycle process that encompasses every aspect of its development and release processes, and the underlying ecosystem required for the products to function.
Measuring Twice
You can’t change what you don’t measure. In DevSecOps adoption we must measure your starting point to establish the end goal and success along the journey. At Oteemo, we begin by measuring customer capabilities, and then create blueprints that target specific enhancements to abilities while also measuring the impact on the lifecycle of software. These measurements have been very successful in prioritizing change and shortening the time-to-value for customers.
Below is a shortlist of the core DevSecOps measurements Oteemo uses to start the DevSecOps journey. The number of metrics depending on your processes and scope: these are the core metrics targeted for a standard adoption process in working with a software team.
| Agile | Product | Security |
| Lead time from story creation to production | Automated Unit Test Coverage | Security Findings – Code Level |
| Cycle time “in progress” | Automated Functional/Regression Test Coverage | Security Findings – Dependencies Level |
| Story time in backlog | Automation Test Pass/Fail Percentage | Security Findings – OS/Base-image Level |
| Done story to production time | Automation Test Pass/Fail Percentage | Security Findings – Penetration testing |
| Number of prod incidents defects found by internal/external customers | Static Code Quality Findings | Security Findings in Production |
| Number of prod defects found by non-customers | Time to provision infrastructure | Security Incidents in Production |
| Number of defects found before production | Time to set up middleware | Mean Time to Resolve Production Security Findings |
| MTTR (Mean Time to Recovery) – Incident | Deployment pipeline Time | Number of security findings having exceptions |
| MTTR (Mean Time to Recovery) – Defect | Build pipeline Time | Security Audits Passed/Failed |
| Deployment to Sprint Rate | Deployment Cost (in Personnel-Hour) | Security findings in Image Life Cycle |
| Velocity per Sprint | Deployment Error Rate | |
| Scope Change | Deployment Roll Back Rate | |
| Deployment Time to Roll Back | ||
| Application outages by patching cycle | ||
| Application production Uptime – Reported |
Reciprocity and Supportability
How well can your teams support your products? This is an issue that can get lost in the wake of major DevSecOps adoption changes and optimizations. A well-defined, shared-responsibility model for your Agile, Release Engineering, Security and Development teams, among others, involves reliability engineering or SRE. Reliability Engineering teams focus on reducing toil and establishing good practices and SLx(SLO, SLI, SLA) with the larger business. These agreements set expectations around availability and continuous monitoring and improvement and will be described in more detail in a coming post.
DevSecOps Transformation
This term has become somewhat overloaded and can conflate the goals and value offered by a DevSecOps program. That said, the process to implement DevSecOps is transformative by definition. When teams identify their products and customers, and define new ways-of-working through DevSecOps, it is nothing short of transformative! Watching a group of people come together to delight their customers and peers is an amazing experience and I’m always grateful to be a part of it.
What does transformation mean to you? To me, it means that everyone participating in building and delivering products is accountable and enabled to be successful in their efforts. Transforming from an organizational pattern of inflexible and opaque processes to rational clearly understood shared goals and responsibilities.
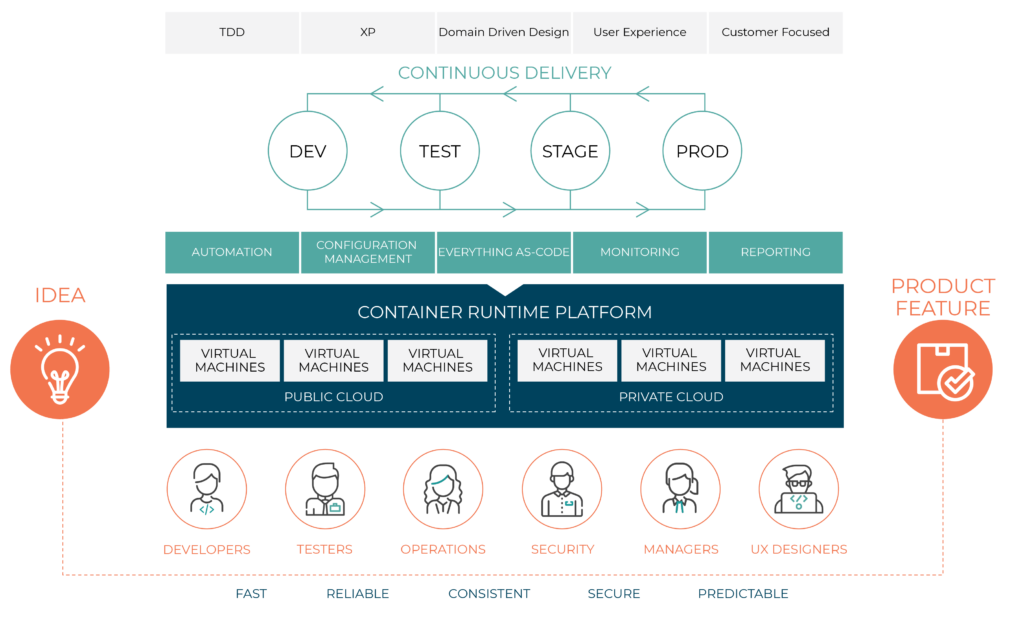
How do you know that your transformation process is working?
Keeping a jaundiced eye on the following measurements can tell you how well or poorly your transformation process is moving along:
- Happy employees (less toil)
- Shortened Time-to-Market on features and new releases
- Increased reliability of services (fewer production defects/outages)
- Improved understanding of shared-goals and responsibilities
These aren’t the only transformation measurements, though in my experience, I believe these are the core set of metrics that tell the story of successful transformation.
When is your transformation complete?
When you reach the point where innovation and safety are baked into all processes and the act of continuous improvement is fully achievable and clearly understood by value chain contributors. You’re never done getting better and optimizing processes and experimenting with new things. The ability to experiment and innovate quickly is the best sign to know that your transformation is working well.






0 Comments