For many companies, the journey to containers has been accelerated through the use of cloud native tools and practices adopted to compliment container management platforms. Traditionally the tools can be grouped into four categories:
- Infrastructure as Code which gives us automation orchestration tools like Ansible and Chef.
- Continuous Integration/Deployment which gives us tools like Jenkins and Vagrant with supporting SCM’s like Git and Subversion.
- Config/Secret management, which gives us tools like Consul and Vault.
- Monitoring where tools like Prometheus and New Relic provide insight and alerts to manage the health of the containers and platform.
Combining these tools to offer a cohesive solution can further accelerate ramp up time of installation, configuration and deployment. The end result is a complete solution to managing the kubernetes cluster and exploiting its capabilities.
Unfortunately, there is a gap. Just as containerization platforms have drastically changed Operations tools and practices, a similar revolution is needed on the Development side. Traditional development practices and tools need to be adopted to take advantage of the capabilities of the platform and of container architecture in general. Development teams aren’t just delivering code anymore, they are delivering self-contained systems designed to be modular and integrated as services. The traditional approach of “commit now integrate later” is no longer optimal for a healthy efficient pipeline. A development environment for a single microservice could require integration with a dozen other microservices making it nearly impossible to recreate on a workstation. For this reason, teams have been moving to shared development environments on the container platform itself which creates concurrency and resource issues as they attempt to accommodate all the iterations of teams, developers, and development efforts. This also adds a great deal of inefficiencies to development workflows as developers have to use operations pipelines to deploy to these environments. A typical workflow in this scenario is: code, commit, push, build, deploy, test. If there’s a problem: recode, commit, push, build, deploy, test. This adds a huge amount of time to each iteration. If you were working on something like JavaScript where you need to quickly iterate to confirm proper browser functionality, it could take an order of magnitude longer than simply developing locally, and this is what ends up happening. Teams will try to do as much locally as is allowable and “hope” it integrates properly when submitted through the pipeline. So we still end up with “well, it works on my laptop”. It’s also worth mentioning developer pain points like access to logs, privileged access to servers for debugging/troubleshooting, and an inability to “fail fast” as these are shared environments.
So how can we empower development teams and allow them to fully realize the capabilities of container platforms? We need a fifth tool category.
1. Infrastructure as Code
2. Continuous Integration/Deployment
3. Config/Secret Management
4. Monitoring
5. Encapsulated Development
Encapsulated Development refers to self-contained single tenant deployment on a container platform. This deployment consists of containers which host a full development environment and dependent containers required for integration with the service/microservice being developed. This environment is accessible only to the individual developer and can be deployed and destroyed/recreated at will. It is completely under source control and runs within the confines of the container platform constrained by any quota and security policies. In the JavaScript use case above, it’s now possible for the developer to make code changes is real-time as they are working directly on the container serving the code, and since the codebase is mounted on the container from a checked-out version from the SCM, the changes are all tracked. This encapsulated environment is also defined in SCM, so all configurations for libraries, tools, plugins, etc. are committed and maintained allowing quick rollout or onboarding for development teams. Cloud-native development now becomes more unified as development teams are now creating and working with the same containers in their environments as deployed everywhere else. Not only can developers “fail fast” without impacting other teams, they get total access to the containers in their environment. Logs, root access, you name it. All without requesting elevated rights or poking holes in security.
Eclipse Che is an elegant solution to bridge this gap and help define Encapsulated Development. Essentially, Che is a cloud-native encapsulated development environment packaged up and deployed to a containerization platform. It runs natively on Kubernetes and Openshift and allows developers individual self-service environments which can be destroyed and recreated easily. It links into existing identity management services and operates completely within the constraints of the platform in terms of quotas and resource management and the client side only requires a browser.

Che is deployed as an application to your container platform with three pods.
- Che – the actual application
- PostgreSQL – the database for storing application settings
- KeyCloak – authentication and access control for Che
KeyCloak connects to your existing identity management solution such as LDAP or AD and, in a pinch, can server as its own identity manager. Depending on the constraints of the environment, it can also manage registrations and user passwords for Che.
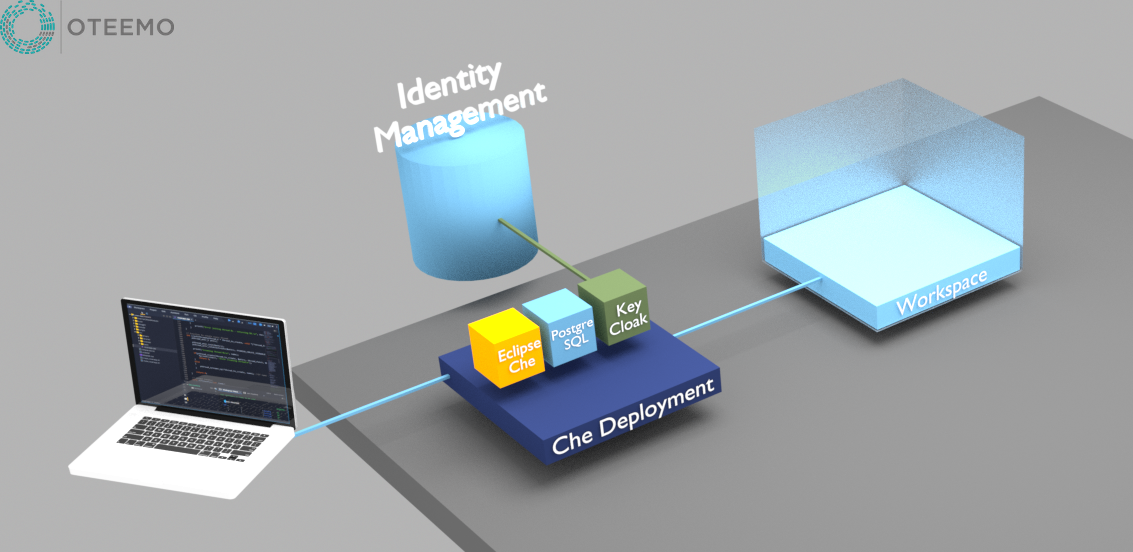
Users connect to Che via a browser to configure and manage workspaces. Workspaces belong to each user and are confined to the namespace configured for Che users. The workspace contains the definitions of what projects and stacks belong to it. These definitions are used by the next layer called the “Stack”.

The stack layer contains information on all the containers, commands, and plugins defined for the workspace. It uses this information to build all the containers for the workspace from repository services and manages connectivity between Che and all components of the environment.
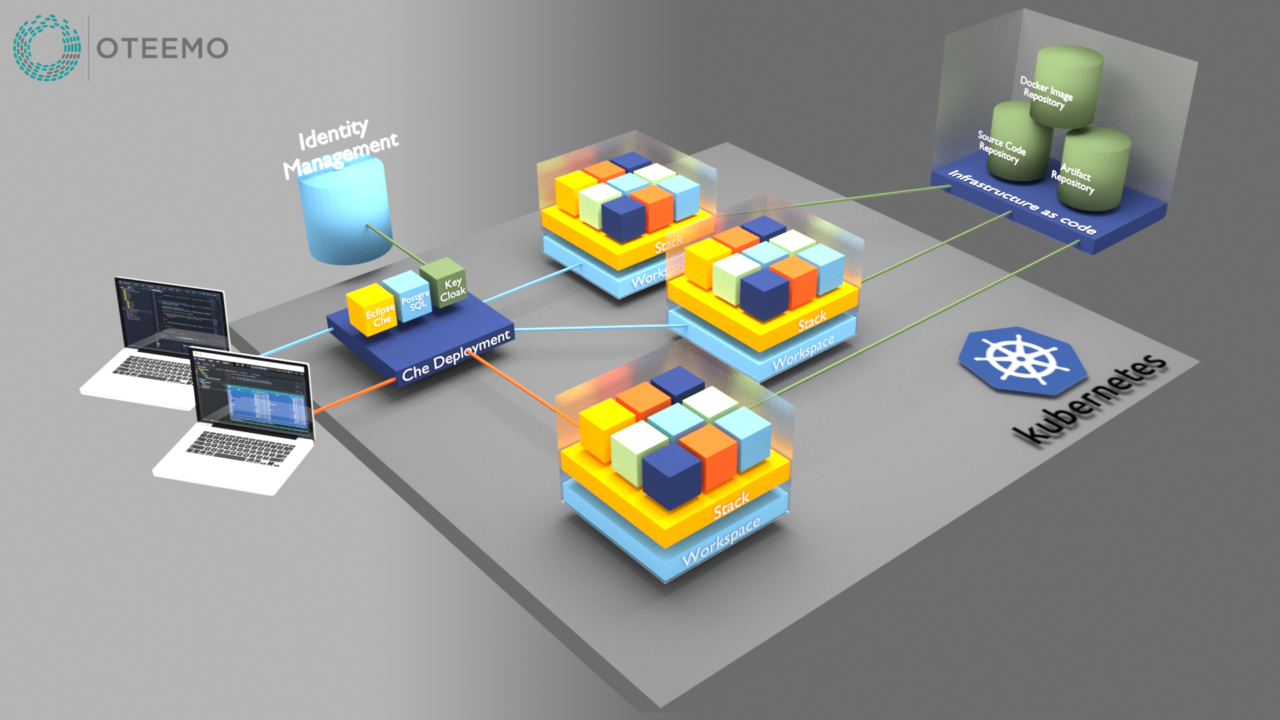
Users can have as many workspaces as needed and can run as many concurrent workspaces as quotas allow. Each individual user workspace is managed by that user and can be created and destroyed at will. Che also offers an extensive API to automate workspace and stack creation and maintenance as well as library and template management. From an infrastructure perspective, Che gives development teams a great degree of flexibility and independence while enabling deep levels of automation both on the user and operations side.
Let’s take a closer look at the Che workspace.
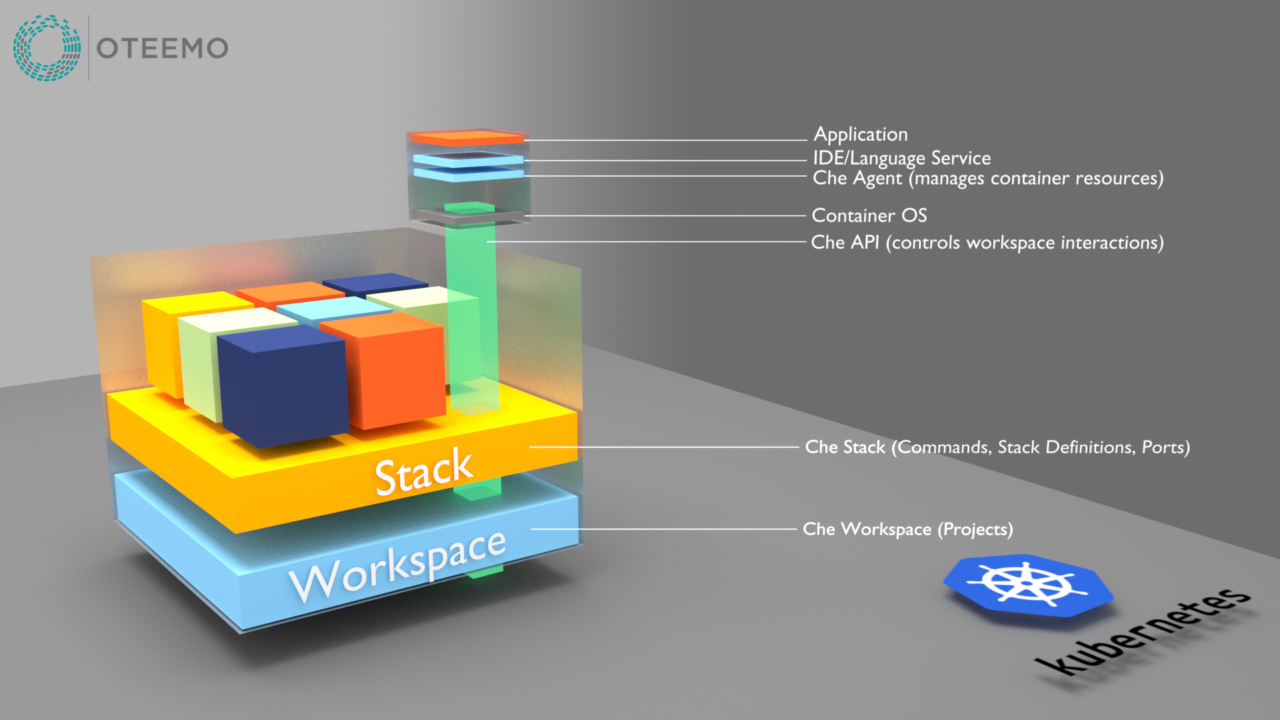
The workspace object itself is simply a logical structure where base components are defined. Basically, it stores the definitions of what’s in the other layers as well as locations of projects and credentials. In addition to container image and port definitions, the stack also stores configurations for each container including; custom commands, plugins, environment variables for each container, etc. This illustration shows a typical Che development container broken out into layers. Along with the containers’ normal OS and application layers are Che injected layers for agents and Che specific services like the IDE and language support among others. Code is deployed directly to this container where it can be modified and debugged through the IDE. Telnet and/or ssh is also available for interacting with the container.
Additional containers deployed in the workspace may have similar injections or simply be default images deployed in the environment for use with the main services being developed like caching or database containers.
The benefits of using Che for development are:
- Self service for development teams
- No compromise of security and operations concerns
- Faster onboarding. (seconds vs weeks)
- No additional support burden for operations
- Customizable development workflows
- Seamless integration into existing container platform
- Development rather than operations centric approach
Che can significantly increase the velocity of development teams by allowing them to iterate faster and shorten feedback loops while developing. From the operations perspective, Che is a “known quantity” and can be supported as any other deployment. Its APIs make automation straight forward and scalable as its use grows within the organization. And it’s also possible to use Che for development of automation tasks, docker image development, and development of custom Che plugins. All of this can be done without hacking together custom solutions.
I believe this is the future of development in a container-centric ecosystem and well worth a look.






0 Comments